概述
首先要理解Base64是一种二进制数据的表示方法,它只是一种表达形式,并不是加密,也不是压缩字符长度。惯例引用wiki概述:
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于2的6次方等于64,所以每6个比特为一个单元,对应某个可打印字符。三个字节有24个比特,对应于4个Base64单元,即3个字节需要用4个可打印字符来表示。它可用来作为电子邮件的传输编码。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。一些如uuencode的其他编码方法,和之后binhex的版本使用不同的64字符集来代表6个二进制数字,但是它们不叫Base64。
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据。包括MIME的email、在XML中存储复杂数据。
转换原理
由于Base64是针对字节进行转码的,对于一般的文本,需要先按照其编码格式转换为字节数组,然后在将字节数组转为Base64串。其实现过程wiki有一个非常直观的表格,如下图

这里注意一点就是字母M在ASCII编码中占一个字节,但是如果在其他编码中不一定是一个字节,所以在转码过程中一定要注意到文本编码的问题,不同编码格式的文本转换出的Base64串也很可能不同
另外,无论是单字节编码还是双字节编码的文本,都会面临一个问题,即一个字节占8比特,8的倍数不能全被6整除,假设上面wiki的例子中只转换字母M(ASCII编码下),M的八位比特位分别是01001101,如果转换Base64的话,前面的010011可以转换为T,但是后面剩下01不足6位,这时候规定是不足6位比特时在后面补0,01后面补4个0就变成010000,对应Base64编码中的Q,但是因为你是补位后的转换,为了和正常的转换进行区分,需要在最后加入一个或两个=
即:
补了4个0的情况,末尾加2个=
补了2个0的情况,末尾加1个=
所以刚才的字母M(ASCII编码下)转为Base64时会变为TQ==
顺便引用一下wiki对于补位的解释和示例

.NET环境下的转码问题
.NET中的Convert类已经封装好了Base64与字节数组的转换方法,分别是
Convert.ToBase64String(byte[] inArray)和Convert.FromBase64String(string s)
.NET中还有一个将字符串转为字节数组的方法叫做Encoding.[编码集].GetBytes(string s)。我之前不理解Base64,不清楚这两个转换方法有什么区别。从.NET的注释来看GetBytes是在派生类中重写时,将指定字符串中的所有字符编码为一个字节序列,而FromBase64String是将指定的字符串(它将二进制数据编码为 Base64 数字)转换为等效的 8 位无符号整数数组,为了明确二者联系,我做了一个实验如下:
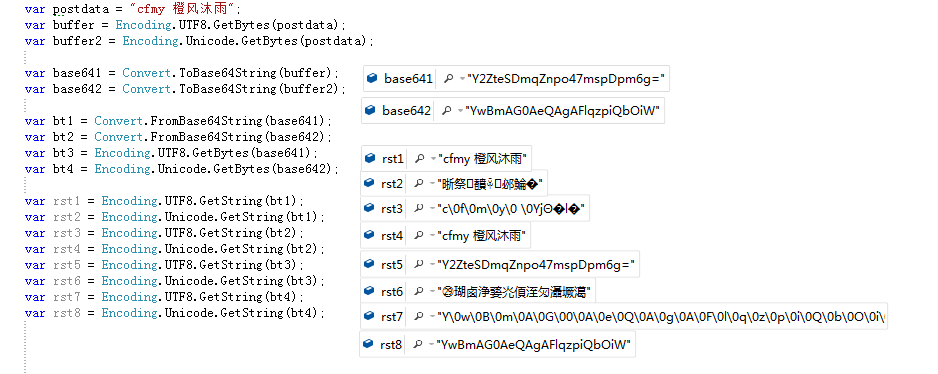
我先讲字符串按照UTF-8和Unicode编码转为字节数组,然后转为Base64,可以看出二者是不同的,然后在按照Base64格式、UTF-8格式和Unicode格式解析为字节数组,最后再把4个字节数组按照UTF-8和Unicode转为字符串,最后生成了8组字符串。
最终成功还原的是rst1和rst4,可以看出这两个其实走的同一个路线,即
Encoding.[编码集].GetBytes() -> Convert.ToBase64String -> Convert.FromBase64String -> Encoding.[相同编码集].GetString
通过这个实验我也理解了GetBytes和FromBase64String虽然入参和出参想同,但其实是两个概念。FromBase64String是先把字符串按照Base64规则(6比特=1字符)转为比特位,然后在按照8比特为一单位进行分割,而GetBytes方法只不过是按照字符的编码格式转成8比特为一单位的数组而已。比如字母M的Base64流为TQ==,用FromBase64String会变为[01001101](十进制为[77]),用GetBytes把每一个字符都转为一个字节,假设是UTF8.GetBytes结果会是[01010100,01010001,00111101,00111101](十进制为[84,81,61,61])
参照
维基百科-Base64:https://zh.wikipedia.org/wiki/Base64